agent记忆
任务:
- 调研当前 [Memory] 常规的设计方案
- 调研当前行业最顶尖的设计方案
- 调研当前行业最前沿的设计方案(可以不落地、纯理念)
包括:
- MAS 运行期间如何保证超长轮次后或超长上下文后,不丢失信息
- 用户长期 Memory 如何离线计算与存储,如何做到精准召回【大海捞针】
- 如何使用 MAS 离线数据做用户数据 RL,增强用户粘性
- 如何使用 MAS 离线数据做系统 RL,构建数据飞轮
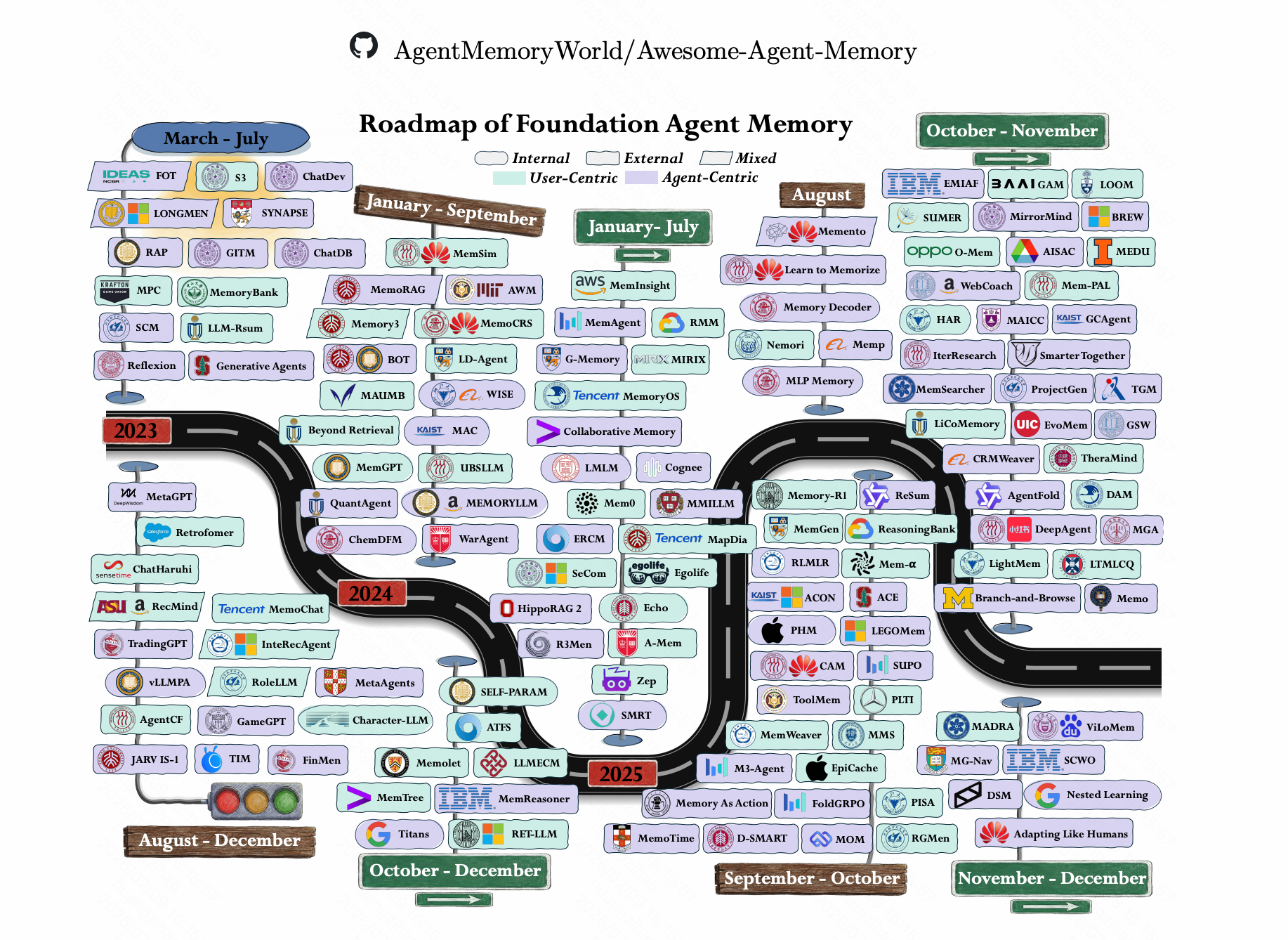
业内通用技术概览
短期记忆
方案:
滑动窗口(结构化与非结构化)
中期记忆
方案:
- 文件系统存储(摘要总结,关键信息)
长期记忆
方案
- Vector-RAG
- 知识图谱(Graph-RAG)
- 其他RAG(T2RAG, HippoRAG2 … …)
- 固定文件存储(Memory.md)
存储内容
动态画像(User Profiling,根据会话提取用户偏好等,存储并放到system prompt)
- 显式偏好(Explicit): 用户直接告诉你的信息(“我不吃香菜”、“我是资深前端”)。
- 隐式偏好(Implicit): 从对话语气、纠错记录中挖掘出的信息(例如:用户多次要求代码简化,推断其偏好“极简主义”)。
- 认知风格(Cognitive Style): 用户理解问题的方式(是喜欢看图表,还是喜欢看长文逻辑?)。
工作记忆(agent与用户经历了什么, 动态搜索)
- 情景记忆:记录的是具体的“事件”和“体验”(例如:昨天下午 3 点和用户讨论了 A 方案)。
- 语义记忆:记录的是沉淀下来的“事实”和“知识”(例如:A 方案的预算是 100 万)。
- 程序性记忆: “如何做”的技能和工作流。
技术相关
传统RAG
传统RAG痛点:
1.逻辑断裂问题:为适配模型上下文窗口,需将文档暴力切分为512词或1000词的碎片(Hard
Chunking),导致原本连贯的语义逻辑被切断,关键信息分散在不同碎片中;
2.匹配偏差问题:依赖语义相似度检索,仅能实现“字面相似”匹配,无法精准捕捉用户“提问意图”与文档“核心内容”的深层关联,常出现“答非所问”;
3.跨域溯源问题:无法理解文档中的跨页参考(如“详见附录G”“参考第2章”),无法像人类一样顺着线索层级溯源,在复杂文档中检索效率极低;
- pageIndex[长期记忆](2025.8)
github url: https://github.com/VectifyAI/PageIndex(14.3k+ star, 1k+fork)
灵感来源(推测):claude code会让ai自主判断搜索哪个文档检索信息(grep、glob、llms.txt文件清单)
检索流程: 自主决策 → 定向搜索 → 按需提取,让ai主动检索长文档。
核心架构: 树形索引
使用LLM将每个文档拆分为层级分明的树状结构(node_id, title, usummary, sub_nodes)
检索时先读目录索引,然后定位原文内容。
缺点: 对文档结构依赖比较高, 多次llm调用时间慢,token消耗多
知识图谱(GraphRAG)
- 什么是知识图谱?
[“我爱吃西瓜”, “我爱吃黄瓜”, “他爱吃西瓜”]
传统rag:
“我爱吃什么”✅
“西瓜出现了几次”❌
知识图谱:
我 ——爱吃——> 西瓜
[实体] [关系] [实体]
- 如何生成知识图谱?
目标:
生成”我喜欢吃西瓜"的LPG
步骤:
1.识别“实体”类型包括“人”“物体”,”味道”
2.识别“实体”间的“关系”
把全部信息交给大模型
大模型返回:
我:人:爱吃瓜
西瓜:水果:我爱吃
我-(爱吃)->西瓜:我爱吃的东西
信息再给大模型确认一遍看有没有要补充的
构建出不同层级的抽象逻辑存到向量库里面
搜索策略多种多样
本质上就是多过大模型处理关系,很消耗token
开源项目分析
- Clawdbot
github url: https://github.com/openclaw/openclaw
介绍文章:https://x.com/manthanguptaa/status/2015780646770323543?ref=dailydev
Context = System Prompt + Conversation History + Tool Results + Attachments
会保留最后几条聊天记录不压缩[短期记忆]🌟
[长期记忆]流程:
第一步:对话全部存下来
你说的每句话,自动写进 memory/日期.md 文件。
关键是文件一改动,就触发 SQLite 更新:
- 文件监听(Chokidar)检测到变化
- 自动分块、向量化、建索引
- 写入五张表:主表、向量索引、全文索引、缓存、元数据
这是持久化层,保证对话不丢。
━━━━━━━━━━━━━
第二步:混合检索精准召回
存下来只是第一步,能快速找到才是关键。
你问:"Alice 负责的项目是啥?"
系统并行跑两路搜索:
- 向量检索(chunks_vec 表):理解语义,"负责"≈"负责人"
- 关键字检索(chunks_fts 表):精确匹配,"Alice"必须一致
然后加权合并:向量 70% + 关键字 30%
为什么要混合? - 单用向量:专有名词容易混淆
- 单用关键字:换个说法就搜不到
- 两者互补,覆盖更多查询场景
━━━━━━━━━━━━━
本质是什么?
建立可检索的知识库,通过文件绑定数据库的方式。
不是把历史对话全塞进 prompt(token 撑不住)
而是按需召回:搜索 → 返回最相关的几条 → 喂给 AI
长期记忆 = 持久化存储 + 精准检索
━━━━━━━━━━━━━
技术栈:
- 存储:Markdown + SQLite
- 向量:OpenAI embedding(1536维)
- 检索:sqlite-vec + FTS5 (BM25)

- opencode
- opencode-openmemory 插件实现长期记忆
- 清理旧记忆时,保留工具调用流程,但是清除observation结果[中期记忆]🌟
- 压缩逻辑prompt[短期记忆]:
You are a helpful AI assistant tasked with summarizing conversations.
When asked to summarize, provide a detailed but concise summary of the conversation.
Focus on information that would be helpful for continuing the conversation, including:
- What was done
- What is currently being worked on
- Which files are being modified
- What needs to be done next
- Key user requests, constraints, or preferences that should persist
- Important technical decisions and why they were made
Your summary should be comprehensive enough to provide context but concise enough to be quickly understood.
优秀文章介绍
- manus文章(2025.7)
内容:
- 不要按需加载工具,选择遮盖而并非移除,否则会导致缓存失效、llm前文掉的工具不存在在现在的对话中,记忆混乱(应该是使用logit_bias参数,降低某些token的生成概率)🌟
“1.In most LLMs, tool definitions live near the front of the context after serialization, typically before or after the system prompt. So any change will invalidate the KV-cache for all subsequent actions and observations.
2.When previous actions and observations still refer to tools that are no longer defined in the current context, the model gets confused. Without constrained decoding, this often leads to schema violations or hallucinated actions.”
- 文件系统作为中期记忆 ✅
- 注意力机制,把任务复述到上下文的末尾,防止越走越偏(todo list架构)🌟
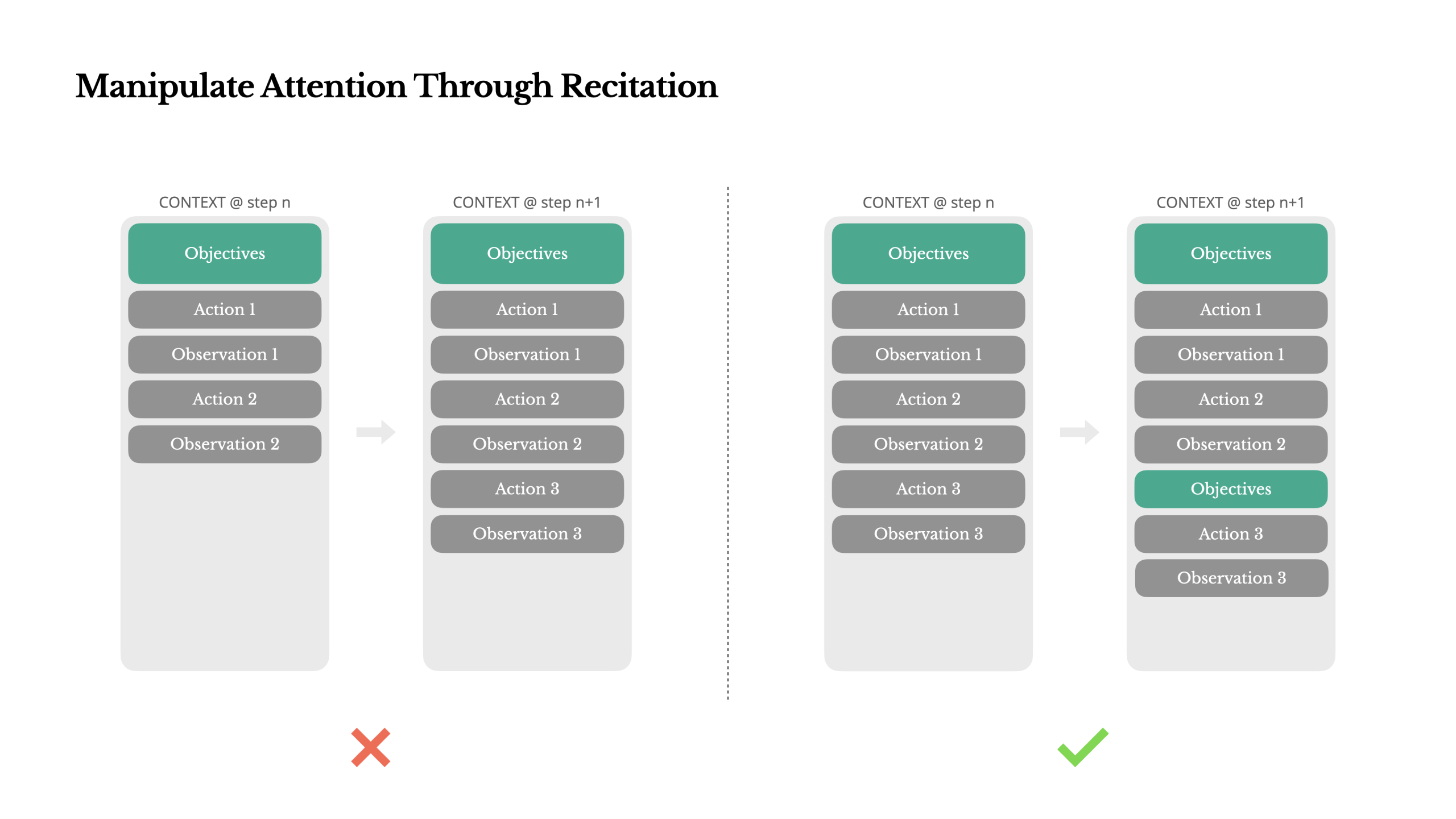
- langchain 《Context Engine》(2025.7)
总结:
- Agent 不仅要能存记忆,还必须按任务选择相关记忆
- 记忆分为三类:
- 语义记忆:事实与知识
- 情景记忆:过去的行为与经历
- 程序记忆:规则、指令、系统提示
- 很多 Agent 通过固定加载少量规则/示例文件来避免复杂的记忆选择(AGENT.md)
- 当记忆规模变大(尤其是语义记忆),记忆选择成为核心难题,常用方法是 Embedding / 知识图谱 做记忆检索
“Memories
If agents have the ability to save memories, they also need the ability to select memories relevant to the task they are performing. This can be useful for a few reasons. Agents might select few-shot examples (episodic memories) for examples of desired behavior, instructions (procedural memories) to steer behavior, or facts (semantic memories) for task-relevant context.

One challenge is ensuring that relevant memories are selected. Some popular agents simply use a narrow set of files that are always pulled into context. For example, many code agent use specific files to save instructions (”procedural” memories) or, in some cases, examples (”episodic” memories). Claude Code uses CLAUDE.md. Cursor and Windsurf use rules files.
But, if an agent is storing a larger collection of facts and / or relationships (e.g., semantic memories), selection is harder. ChatGPT is a good example of a popular product that stores and selects from a large collection of user-specific memories.
Embeddings and / or knowledge graphs for memory indexing are commonly used to assist with selection. Still, memory selection is challenging. At the AIEngineer World’s Fair, Simon Willison shared an example of selection gone wrong: ChatGPT fetched his location from memories and unexpectedly injected it into a requested image. This type of unexpected or undesired memory retrieval can make some users feel like the context window “no longer belongs to them”!”
优秀论文介绍
1.A-mem(2025.2.17 - 2025.10.8)
github:https://github.com/agiresearch/A-mem(828+star, 90+fork)
验证论文结果:https://github.com/WujiangXu/A-mem
较为权威,会被其他论文当作baseline对比
这篇论文提出的 A-MEM 系统主要包含以下四个核心方法步骤:
-
结构化存储
系统不只是存储原始对话,而是基于“卡片盒笔记法”构建结构化的记忆笔记。对于每次交互,系统利用大模型生成包含多个维度的信息,包括原始内容、时间戳、关键词、分类标签以及上下文描述。这种结构化的方式能够捕捉记忆的深层语义,便于后续的检索和管理 -
关联信息链接
1.A喜欢吃水果 ↔ 2.B喜欢的和A喜欢的一样。提问:B喜欢吃什么
召回时同时召回两条数据
当新记忆产生时,系统会自动寻找并建立它与历史记忆之间的联系。首先通过向量相似度检索出最相关的历史笔记,然后利用大模型分析这些笔记之间的潜在关联(如因果关系或共同属性),从而建立起动态的知识网络,而不是仅仅依赖预定义的规则。 -
记忆进化
允许旧记忆随着新信息的输入而更新。在检索到相关的历史记忆后,系统会判断新信息是否能完善旧记忆的上下文、关键词或标签。如果需要,系统会生成进化后的新版本来替换旧记忆,模拟人类不断通过新经验完善旧知识的学习过程。 -
相关记忆检索
在实际回答用户问题时,系统采用基于向量的检索机制。系统将当前的查询转换为向量,计算其与记忆库中所有笔记的相似度,并提取相关性最高的 Top-k 个记忆笔记。这些检索到的记忆会被作为上下文提供给智能体,帮助其生成更准确、连贯的回答。 -
MemSkill(2026.2.2)
arxiv:
关键点:
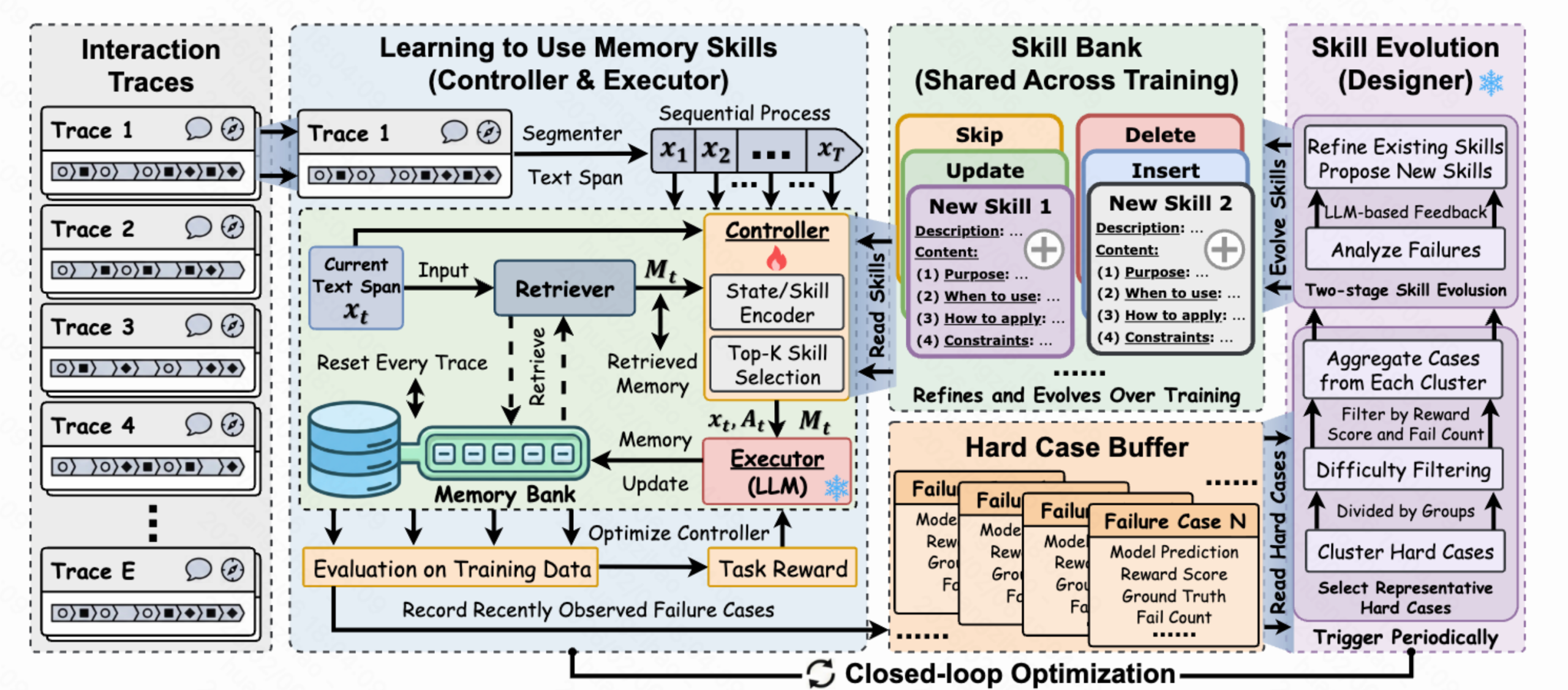
论文核心思想
MemSkill 将 LLM Agent 的记忆操作从静态手工设计转变为可学习、可进化的技能。核心组件包括:
- Skill Bank:可复用的记忆技能库
- Controller:基于语义相似度的 Top-K 技能选择器
- Executor:技能条件化的记忆构建器
- Designer:从困难案例中进化技能的优化器
skill结构体如下,选好后让大模型生成结构化文本,解析器再去解析


亮点:
切分策略(按照span切分):
- 按token切分span,在每两个span中有重叠的token部分
- 按照轮数切分(thinking→action→observation算一次span)
记忆存储策略不再依赖在代码写死(例如cheerlink固定prompt压缩event_stream)
case
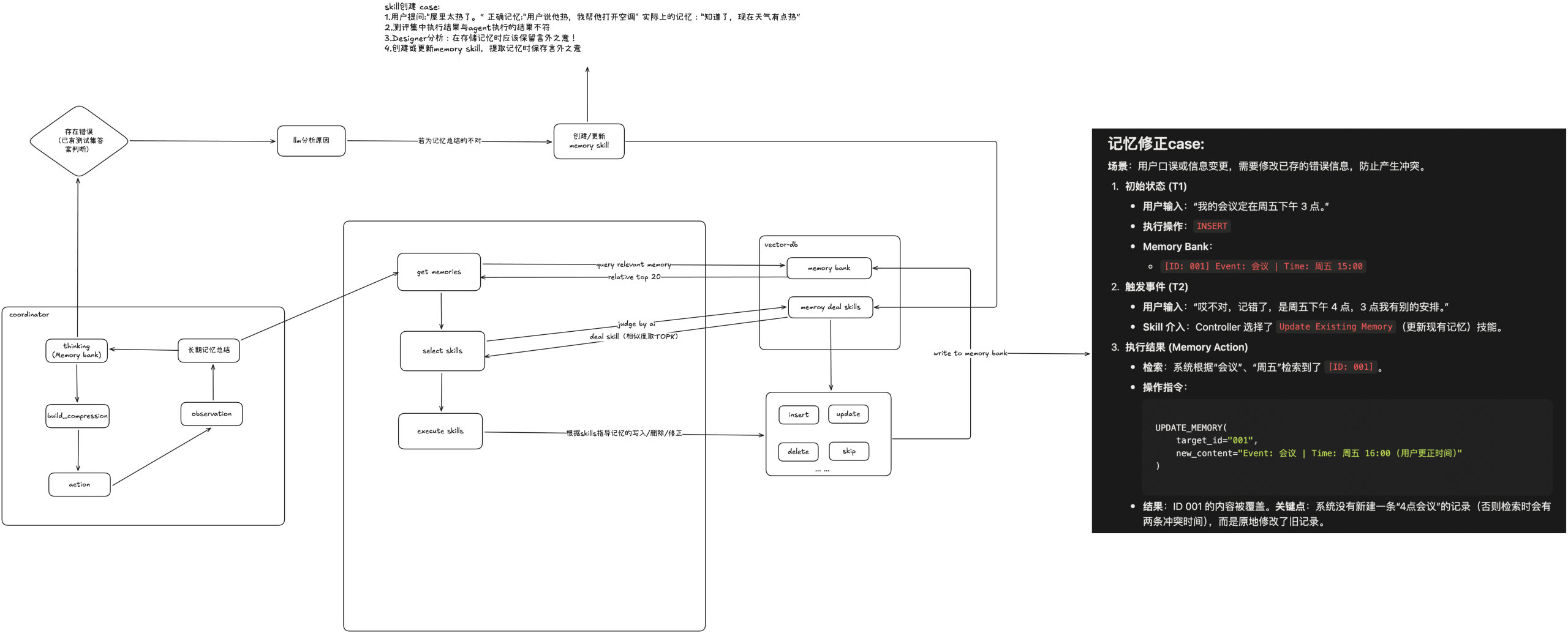
skill创建 case:
“言外之意”skill
1.用户提问:“屋里太热了。” 正确记忆:“用户说他热,我需要帮他打开空调" 实际上的记忆:“知道了,现在天气有点热”
2.经过了很多轮对话之后,测评集中执行结果与agent执行的结果不符(因为记忆中未存储言外之意)
3.Designer分析:在存储记忆时应该保留言外之意!
4.创建或更新memory skill,提取记忆时保存言外之意
“时间线提取skill”
历史记录的提取只保存先后顺序未保存具体的时间导致的错误
… …
记忆修正case:
场景:用户口误或信息变更,需要修改已存的错误信息,防止产生冲突。
- 初始状态 (T1)
- 用户输入:“我的会议定在周五下午 3 点。”
- 执行操作:
INSERT - Memory Bank:
[ID: 001] Event: 会议 | Time: 周五 15:00
- 触发事件 (T2)
- 用户输入:“哎不对,记错了,是周五下午 4 点,3 点我有别的安排。”
- Skill 介入:Controller 选择了
Update Existing Memory(更新现有记忆)技能。
-
执行结果 (Memory Action)
-
检索:系统根据“会议”、“周五”检索到了
[ID: 001]。 -
操作指令:
UPDATE_MEMORY( target_id="001", new_content="Event: 会议 | Time: 周五 16:00 (用户更正时间)" ) -
结果:ID 001 的内容被覆盖。关键点:系统没有新建一条“4点会议”的记录(否则检索时会有两条冲突时间),而是原地修改了旧记录。
-
INSERT_MEMORY(
content="Preference Details: 喜欢苹果、香蕉; 讨厌榴莲"
)
3.SimpleMem(2026.1.5-2026.1.29)
github:https://github.com/aiming-lab/SimpleMem(2.7k+ star, 276+ fork)
arxiv:
SimpleMem: Efficient Lifelong Memory for LLM Agents
一个基于语义无损压缩的高效记忆框架,旨在解决大语言模型(LLM)智能体在长期交互中面临的记忆冗余和高昂的 Token 成本问题。
论文提出了三个阶段的流水线:
1. 语义结构化压缩 (Semantic Structured Compression)
他下午三点吃饭 → 子皓在2026年2月9号下午三点吃饭
这一步主要负责“清洗”和“标准化”进入系统的原始对话,防止垃圾信息污染记忆库。
它首先通过一个熵感知过滤器来判断每一段对话的“含金量”。系统会计算新对话中出现了多少新实体(比如新人名、新地点)以及它与之前记忆的语义差异。如果一段对话全是“好的”、“收到”这种低熵值的废话,系统会直接将其丢弃,不予存储。
对于通过筛选的有价值信息,系统会进行原子化和去语境化处理。这包括两个关键操作:一是指代消解,把模糊的代词(如“他”)替换成具体的名字(如“Bob”);二是时间锚定,把相对时间(如“下周五”)转换成绝对的 ISO 时间戳(如“2025-10-24”)。这样做的目的是让每一条记忆都变成独立的、不依赖上下文的事实,方便后续单独检索。
(case:假设用户在周五下午发消息说:“好的,收到。顺便提醒我下周一给他发邮件。”系统首先会识别出“好的,收到”属于低熵值的确认性语句,直接将其过滤掉,不占用存储空间。接着,系统处理后半句的高价值信息:它通过上下文分析将代词“他”指代消解为具体的联系人“David”,并将相对时间“下周一”转换为绝对的 ISO 时间戳“2023-11-13”。最终,存入记忆库的不是原始的那句话,而是一条清晰、独立的结构化数据:“用户需要在 2023-11-13 给 David 发送邮件。” )
2. 递归记忆整合 (Recursive Memory Consolidation)
异步整合相似记忆
这一步解决了“随着时间推移,记忆库会变得臃肿”的问题。它模仿了人类大脑将短期记忆转化为长期记忆的过程。
这是一个在后台运行的异步过程。系统会不断扫描已有的记忆单元,计算它们之间的相似度。这里使用了一个亲和度评分(Affinity Score),结合了语义相似度(两件事意思是否相近)和时间接近度(两件事是否在大致相同的时间发生)。
当系统发现一组高度相关的记忆时(例如用户在不同日期的早上都点了咖啡),它不会保留每一条琐碎的记录,而是通过 LLM 将它们合成为一个更高级的抽象记忆(例如“用户习惯在早晨喝咖啡”)。这种机制将无数具体的碎片化事件压缩成了少量的规律性知识,极大地减少了存储空间的占用,同时保留了核心信息。
(case:周一记录了“用户吃了鸡肉沙拉”,周三记录了“用户做了烤鸡胸肉”,周五记录了“用户点了炸鸡外卖”。在后台运行的整合过程会检测到这三条记忆在语义上高度相关(都涉及“鸡肉”和“晚餐”)且在时间上接近。系统不会无限期地保留这三条琐碎的记录,而是将它们合并为一个更高级的抽象记忆:“用户本周的晚餐偏好以鸡肉为主。”这种操作极大地压缩了存储空间,同时让智能体掌握了用户的饮食习惯这一更高层级的规律。)
3. 自适应查询感知检索 (Adaptive Query-Aware Retrieval)
根据任务复杂程度决定检索的记忆数量值
这一步负责在回答问题时,用最少的 Token 找到最准确的答案。传统的系统通常是固定检索前 K 个相关片段,这往往不是太多就是太少。
SimpleMem 首先使用混合评分机制来寻找相关记忆。它不只看语义向量相似度,还会同时检查关键词匹配(Lexical)和元数据约束(Symbolic,如时间范围或实体类型),确保检索结果既符合语境又精准匹配细节。
更重要的是,它引入了一个<查询复杂度估计器>。系统会预先判断用户的问题是简单的“事实查阅”(如“某人的生日是哪天?”)还是复杂的“多跳推理”(如“基于上次的讨论,我们今天的计划应该怎么调整?”)。如果是简单问题,它只检索少量最相关的摘要;如果是复杂问题,它会自动扩大检索范围,纳入更多细节。这种动态调整确保了每一分计算资源都用在刀刃上。
(case:如果用户问:“David 的邮箱是多少?”,系统判定这是一个低复杂度的简单事实查询,因此它会收缩检索范围,仅精准提取包含 David 联系方式的那一条记忆单元。但如果用户问:“考虑到我这周吃了很多鸡肉,这周末我应该尝试什么不同的菜系?”,系统会判定这是一个高复杂度的推理问题。它会自动扩大检索范围,不仅检索之前的“鸡肉偏好”这一整合记忆,还会检索用户过去的“周末活动”记忆和“喜欢的其他菜系”记忆,从而构建一个丰富的上下文来提供建议。)
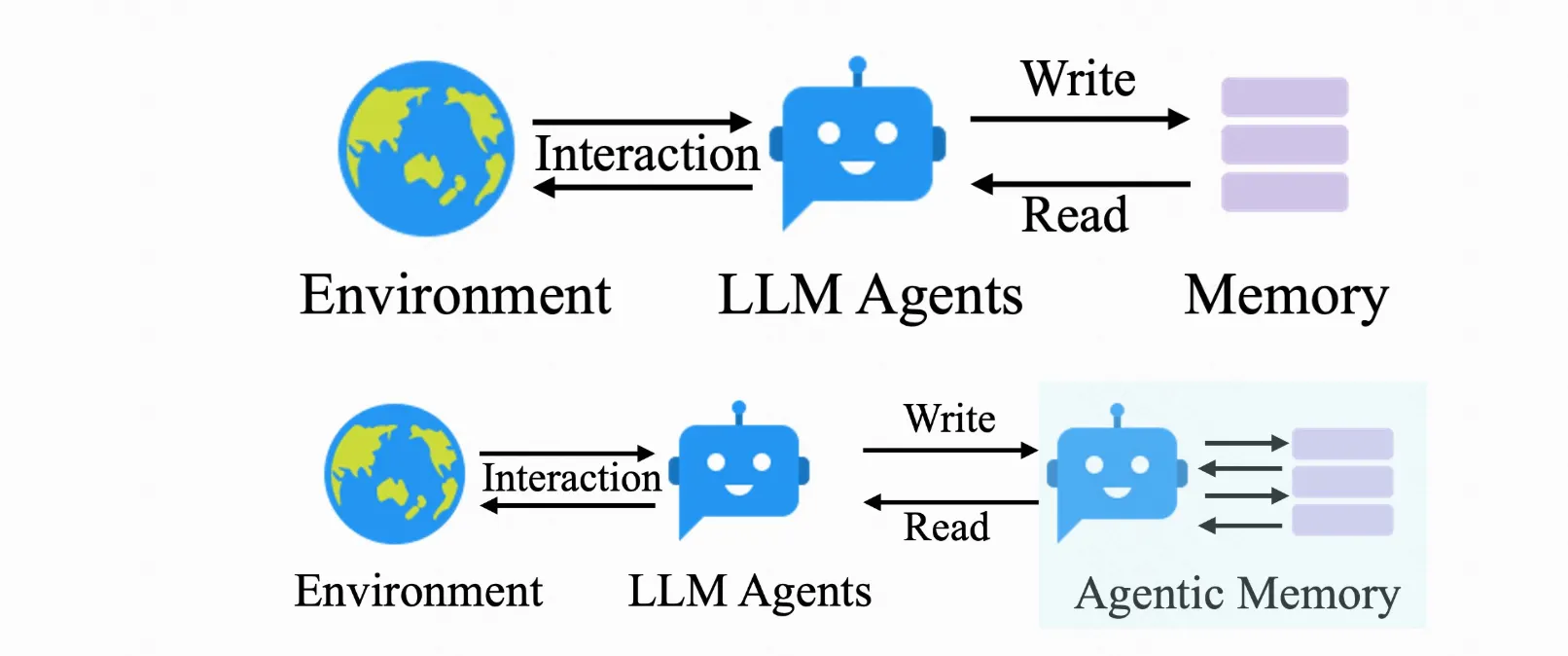
4.Agentic Memory(2026.1.5)
arxiv:
Agentic Memory: Learning Unified Long-Term and Short-Term Memory...
1. 统一的记忆管理框架 (Unified Memory Management)
AgeMem 打破了传统方法将长期记忆(LTM)和短期记忆(STM)作为独立模块处理的模式。它将这两种记忆的管理直接整合到 Agent 的决策策略中,使 Agent 能够根据当前任务的需求,自主且协同地管理这两类记忆。
2. 基于工具的记忆操作接口 (Tool-Based Interface)
为了让大语言模型(LLM)能够执行具体的记忆动作,AgeMem 将记忆操作定义为一组工具。Agent 可以像调用计算器一样调用这些工具:
- 长期记忆工具: 包括
ADD(新增知识)、UPDATE(修改知识)和DELETE(遗忘无用知识)。 - 短期记忆工具: 包括
RETRIEVE(检索信息到上下文)、SUMMARY(压缩上下文)和FILTER(过滤无关信息)。
以下为模型训练相关
3. 三阶段渐进式强化学习策略 (Three-Stage Progressive RL)
为了训练 Agent 学会这些复杂的操作,论文设计了一个分阶段的训练流程,逐步培养能力:
- 阶段 1 (LTM Construction): 在对话中识别重要信息并存入长期记忆。
- 阶段 2 (STM Control): 在引入干扰信息的情况下,学习通过总结和过滤来维护短期上下文。
- 阶段 3 (Integrated Reasoning): 结合前两个阶段的能力,利用检索到的长期记忆和精简的短期上下文来完成最终推理任务。
4. 分步式 GRPO 优化算法 (Step-wise GRPO)
针对记忆操作带来的奖励稀疏和不连续问题(例如,早期的存储操作要等到最后任务完成才能验证其价值),论文提出了一种改进的 GRPO 算法。该算法计算最终的任务奖励,并将其广播回整个轨迹的所有步骤。这确保了早期的记忆管理行为(如第一阶段的存储)也能获得来自最终任务成功的反馈信号。
5. 多维度的奖励函数设计 (Composite Reward Function)
为了引导 Agent 形成良好的记忆习惯,训练不仅仅依赖任务是否成功,还引入了多维度的奖励信号:
- 任务奖励:评估最终答案的准确性。
- 上下文管理奖励:鼓励压缩上下文长度并惩罚关键信息丢失。
- 记忆管理奖励:评估存储内容的质量、维护操作的有效性以及检索的相关性。
5.Memory in the Age of AI Agents
survey 级权威,领域定义者
arxiv:
Memory in the Age of AI Agents
一、 记忆的形式 (Forms):记忆存在哪里?(存储形式)
这一维度关注记忆的物理载体和组织结构,即记忆是以何种形态存储的。
1. Token 级记忆 (Token-level Memory)
这是目前最主流的形式,记忆以显式、离散的 Token(如文本、代码)形式存储在外部,可以被直接读取和编辑。根据结构复杂度分为三类:
- 扁平记忆 (Flat, 1D): 没有拓扑结构,通常以列表或序列形式存储。例如直接拼接对话历史或简单的经验池。
- 平面记忆 (Planar, 2D): 在单一层级内有拓扑结构(如树或图),建立了节点间的关联。例如知识图谱(Knowledge Graph)或树状索引。
- 层级记忆 (Hierarchical, 3D): 具有多层级的立体结构,支持跨层级的抽象和推理。例如分层的摘要金字塔,底层是细节,顶层是高度抽象的概念。
2. 参数化记忆 (Parametric Memory)
记忆被隐式地存储在模型的神经网络参数中,通过训练或微调注入。
- 内部参数记忆: 直接修改模型的主干参数(如 Weights 和 Biases)来注入知识。
- 外部参数记忆: 使用额外的参数模块(如 LoRA、Adapters)来存储记忆,不改变原有模型权重,更灵活且不仅限于训练阶段。
3. 隐层记忆 (Latent Memory)
记忆以连续的向量(Embeddings)或隐藏状态(Hidden States)形式存在,通常是机器原生的表示,人类不可读但计算效率高。
- 生成 (Generate): 使用辅助模型生成压缩的 Latent 向量作为记忆。
- 复用 (Reuse): 直接复用推理过程中的 KV Cache 或激活值,不进行压缩。
- 变换 (Transform): 对现有的 KV Cache 进行压缩、选择或投影,以减少显存占用。
二、 记忆的功能 (Functions):记忆用来做什么?(内容形式)
这一维度关注记忆在 Agent 任务中扮演的角色和目的。
1. 事实记忆 (Factual Memory)
用于存储声明性的知识,解决“Agent 知道什么”的问题。
- 用户事实: 记录用户的画像、偏好、历史对话,确保交互的一致性。
- 环境事实: 记录世界知识、文档状态、其他 Agent 的状态,确保对外部世界认知的连贯性。
用于存储过程性的知识,即“如何解决问题”,支持 Agent 的持续学习和进化。 - 基于案例 (Case-based): 存储原始的交互轨迹(Trajectories)或解决方案,用于直接模仿。
- 基于策略 (Strategy-based): 存储从历史中提炼出的高级规则、工作流(Workflows)或思维模板。
- 基于技能 (Skill-based): 将经验转化为可执行的代码、API 或工具函数(如 Voyager 中的技能库)。
3. 工作记忆 (Working Memory)
用于当前任务的临时信息处理,相当于 Agent 的“草稿纸”或“内存”。
- 单轮工作记忆: 在单次推理中处理超长上下文(如文档压缩、关键信息提取)。
- 多轮工作记忆: 在多轮交互中维护任务状态、目标和进度,防止遗忘当前任务目标。
三、 记忆的动态 (Dynamics):记忆如何运作?
(生命周期,提取 → 更新(删除) → 检索)
这一维度关注记忆系统的生命周期,即记忆是如何产生、演变和被使用的。
1. 记忆形成 (Formation)
将原始数据转化为记忆的过程。方法包括:
- 语义摘要: 提取核心信息,去除冗余。
- 知识蒸馏: 从轨迹中提炼规则或洞察。
- 结构化构建: 将非结构化文本转化为图谱或树。
- 隐层表示: 编码为向量。
- 参数内化: 通过梯度更新写入模型权重。
2. 记忆演化 (Evolution)
记忆库的动态维护,不仅仅是“增加”,还包括:
- 整合 (Consolidation): 将新旧记忆融合,形成更高层的抽象或洞察。
- 更新 (Updating): 解决新旧记忆的冲突,修正错误信息。
- 遗忘 (Forgetting): 基于时间、频率或重要性,删除低价值信息以释放空间。
3. 记忆检索 (Retrieval)
决定如何在推理时使用记忆。
- 时机与意图: 决定“何时”检索(自动触发 vs 被动触发)以及“检索什么”。
- 查询构造: 将用户 Query 重写或分解,以匹配存储的记忆格式。
- 检索策略: 词汇检索(关键词)、语义检索(向量相似度)、图检索(游走算法)或混合检索。
- 后处理: 对检索结果进行重排序(Reranking)、过滤或聚合。
Enjoy every single day